











































Diventa free member
Vuoi leggere questo articolo e le altre notizie e approfondimenti su Ninja? Allora registrati e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.![]()
Diventa free member
Vuoi leggere questo articolo, le altre notizie e approfondimenti su Ninja? Allora lascia semplicemente nome e mail e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.
L’obiettivo di ogni SEO specialist è quello di posizionare le pagine del proprio sito tra i risultati di ricerca, possibilmente nella prima pagina della SERP, dove hanno maggiore probabilità di essere cliccate.
Per far sì che ciò avvenga, i contenuti della pagina devono soddisfare la query inserita nella barra del motore di ricerca dall’utente, ovvero saper intercettare il search intent sulla base di un criterio di pertinenza.
Dal punto di vista della SEO tecnica, si traduce in un’operazione ben precisa: rendere le pagine del sito ben leggibili dal crawler del motore di ricerca.
Il crawler (o web crawler o spider) è un bot del motore di ricerca che esegue una scansione periodica dei contenuti presenti nel web, al fine di raccogliere informazioni dalle pagine e aggiungerle al suo indice.
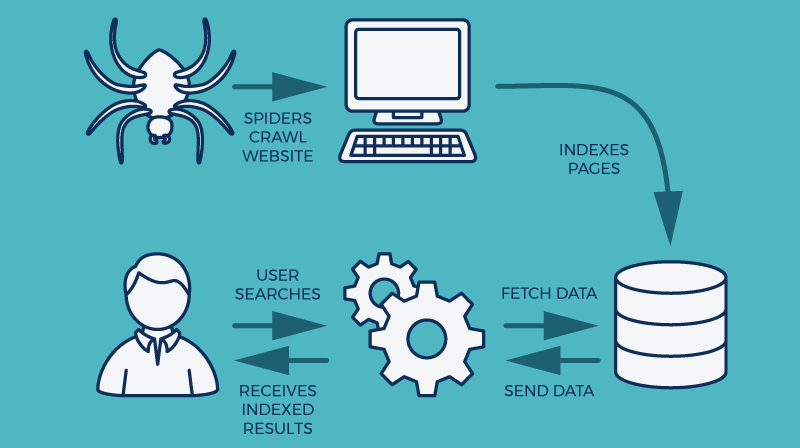
L'indicizzazione di un sito all’interno del web si svolge in 3 fasi:
L’intero processo fa sì che quando la query viene inviata, in una frazione di secondo viene restituita una pagina contenente dei risultati posizionati per pertinenza e/o rilevanza.
Il crawling è la prima fase dell’indicizzazione, in cui tutti i contenuti presenti all’interno del web vengono passati in rassegna e ordinati all’interno di un database da un bot, che li classifica soffermandosi su elementi quali: il SEO title, la meta description, gli alt text delle immagini, le parti in grassetto o in corsivo del testo e i link.
Il crawler si sposta da una pagina all'altra seguendo i link interni e li utilizza per costruire la mappatura del sito e creare una gerarchia in base ai contenuti con un maggior numero di rimandi.

Il processo di crawling è iterativo, il che vuol dire che lo spider ritorna a intervalli regolari su pagine già scansionate alla ricerca di variazioni e nuovi contenuti. Ogni volta che il sito viene aggiornato il crawler salva l’ultima versione.
In sostanza, crawlability vuol dire leggibilità del sito da parte del crawler. La capacità del crawler di accedere a una pagina e scansionarla correttamente rivela se il sito è stato ottimizzato nel modo giusto o, al contrario, sono presenti problemi di indicizzazione. In tal caso, il sito potrebbe non può comparire nei risultati di ricerca organici.
Inoltre, non è fondamentale che tutte le pagine del tuo sito web vengano scansionate: una pagina di contatto o una pagina di accesso all’area riservata, ad esempio, sono inutili ai fini dell’indicizzazione, poiché riservate a una nicchia di utenti.

Il tempo e le risorse del web non sono illimitati, ragion per cui nel processo di indicizzazione il crawler si trova a dare priorità ad alcune pagine rispetto ad altre, a selezionare i contenuti sottoposti a scansione e ignorare il resto.
Per ottimizzare il crawl budget o budget di scansione a tua disposizione, puoi contrassegnare queste sezioni meno rilevanti con il tag noindex, orientare la lettura con i tag canonici, limitarne la lettura mediante il set-up del file robots.txt.
Se hai ricercato keyword, target, creato contenuti pertinenti ma il tuo sito non risulta indicizzato correttamente e non hai un ritorno in termini di traffico, è molto probabile che si tratti di un problema di scansione.

Saper individuare tutti gli elementi che ostacolano o limitano l’accesso del crawling è fondamentale per far sì che il sito venga indicizzato correttamente.
Quali sono i più comuni problemi di crawlability?
La prima cosa che un bot cerca sul tuo sito è il tuo file robots.txt, all’interno del quale puoi indirizzare il crawler, specificando "non consentire” sulle pagine che non desideri vengano scansionate.
Il file robots.txt è molto spesso la causa dei problemi di scansione di un sito. Se le sue direttive sono errate, possono impedire a Google di eseguire la scansione delle tue pagine più importanti o permettere la lettura di quelle inutili ai fini dell’indicizzazione.
Puoi individuare il problema dal “rapporto sulle risorse bloccate” di Google Search Console, che mostra un elenco di host che forniscono risorse al tuo sito, che risultano bloccate dalle regole file robots.txt.

LEGGI ANCHE: La regola dei 15 secondi: ecco perché gli utenti lasciano il tuo sito
Il codice errore 500 rivela un problema del server su cui il sito è ospitato, mentre l’errore 404 dipende dal contenuto del sito stesso.
In entrambi i casi, se Google incontra questi errori quando arriva alla pagina è un grosso problema. Dal momento che viaggia seguendo i link, per il crawler è come trovarsi in un vicolo cieco.
Dopo aver raggiunto un numero elevato di pagine di errore, il bot smette di eseguire la scansione della pagina e del tuo sito.
Anche questo tipo di errore può essere individuato facilmente tramite la Search Console di Google.
Una cattiva indicizzazione può dipendere anche da un uso sbagliato dei tag, se risultano potenzialmente fuorvianti per la lettura del bot, o se sono mancanti, errati o duplicati.
Un metodo veloce per individuare il problema è analizzare il traffico sul sito, principalmente il percorso degli utenti. Le pagine con la frequenza di rimbalzo più elevata possono rivelare delle criticità.
Analizza anche le funzionalità di scansione avanzate della Search Console che mostrano quanti link interni vengono reindirizzati a una sola pagina. Fai attenzione agli elementi di best practice in questo passaggio, come l'assenza di reindirizzamenti 301 interni, la corretta impaginazione e le mappe dei siti complete.
L’usabilità sui dispositivi mobili è un’area di primaria importanza per la SEO: se il sito non è ritenuto utilizzabile su smartphone e tablet, Google potrebbe non mostrarli nella SERP e questo comporta la perdita di una bella fetta di traffico.
Questi problemi possono essere svelati anche dallo strumento della Search Console Google mobile friendly tester.

È buona norma anche controllare sempre l’output dal lato mobile non solo quando il sito viene rilasciata, ma anche ogni volta che viene aggiornata una singola pagina.
Se dopo aver verificato tutti gli elementi di cui sopra, il tuo sito presenta ancora problemi, è possibile che i contenuti delle pagine non siano considerati rilevanti.
Le pagine che presentano contenuti scarni non vengono tralasciate da Google nel processo di scansione, perché il contenuto non è abbastanza unico, non convalida i contenuti di altri siti giudicati autorevoli in quel settore oppure i collegamenti interni sono assenti o scarsi.
Oltre ad analizzare il contenuto non indicizzato e curare la strategia di backlink verso le pagine che non ricevono traffico, è bene aggiornare periodicamente le pagine con contenuti nuovi e dati recenti.
È buona norma anche controllare sempre l’output dal lato mobile non solo quando il sito viene rilasciata, ma anche ogni volta che viene aggiornata una singola pagina.









