Google ha creato una tecnologia che riconosce (e separa) le voci nei video
I ricercatori di Google hanno presentato un modello di deep learning per isolare un singolo segnale vocale da una miscela di suoni
16 Aprile 2018
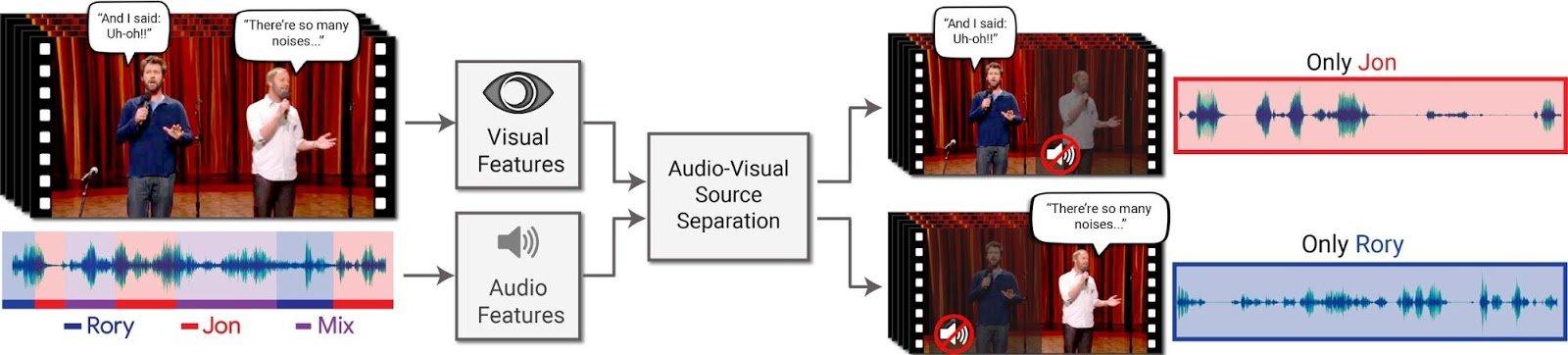
I ricercatori di Google hanno sviluppato un sistema progettato per aiutare i computer a isolare e identificare singole voci all’interno di un ambiente rumoroso. Una folla, per capirsi. Uno dei team all’opera ha tentato di replicare la capacità del nostro cervello di concentrarsi su una fonte audio, filtrando gli altri suoni. Il metodo di Google utilizza un modello audio-visivo, quindi è principalmente incentrato sull’isolamento delle voci nei video.
Test su 100 mila video
La componente visiva di questo sistema è fondamentale: la tecnologia osserva infatti i movimenti della bocca di una persona per identificare meglio le voci su cui concentrarsi in un dato punto e per creare tracce vocali individuali più accurate. I ricercatori hanno sviluppato questo modello raccogliendo 100 mila video di “conferenze e discorsi” su YouTube, estraendo quasi 2 mila ore di segmenti da quei video con un discorso senza ostacoli, quindi mixando quell’audio per creare un “synthetic cocktail party” con rumore di sottofondo artificiale aggiunto.
Machine Learning
Big G ha anche insegnato alla tecnologia a dividere quell’audio misto leggendo le “miniature facciali” delle persone che parlano in ciascun fotogramma video. Il sistema a questo punto è in grado di selezionare quale sorgente audio appartiene a quale faccia in un determinato momento e creare tracce vocali separate per ciascun altoparlante.
Le applicazioni possibili
“Una vasta gamma di applicazioni per questa tecnologia” che “sta attualmente esplorando le opportunità per incorporarlo in vari prodotti”. Queste le dichiarazioni di Mountain View a proposito delle possibili applicazioni. A partire da Hangouts e YouTube, tra le ipotesi anche la possibilità di sviluppare questa tecnologia con insieme a smart glasses.
Pronto a cominciare?
Il tuo futuro nel digital inizia con un passo. Entra nel Campus Ninja