Dobbiamo davvero temere le intelligenze artificiali quanto gli umani?
Non solo ci ruberanno il lavoro, ma se copieranno gli uomini diventeranno razziste, ciniche e sessiste
14 Febbraio 2018
Di intelligenza artificiale se ne parla ormai da decenni: il famoso test per individuare una AI fu proposto da Alan Turinggià nel 1950.
Il rapido sviluppo tecnologico e il miglioramento delle condizioni di vita hanno poi permesso una diffusione massiva di strumenti elettronici e applicazione software. Ora che i sistemi artificiali sono largamente diffusi nel nostro quotidiano, riemergono antichi timori anticipati dalla fantascienza e dai moderni luddisti in un distopico futuro: l’umanità schiava delle macchine e delle intelligenze artificiali, disoccupata, annoiata e inebetita.
Si tratta solo di una visione troppo catastrofica o dovremmo realmente fare attenzione?
I disastri dell’intelligenza artificiale
A sentire i grandi colossi come Google, Amazon e Facebook che ne fanno già largo uso, sembrerebbe che le AI possano offrirci un mondo migliore, senza fakenews, con assistenti digitali sempre a disposizione per risolvere ogni nostro problema e desiderio (magari!) e automobili che ci portano a destinazione in totale sicurezza. Addirittura prevedendo ed evitando incidenti prima che accadano. Ma è davvero così?
In rete si trovano tantissimi filmati (molti anche fake) in cui si vede una Tesla evitare un incidente. Questo video del 2016, che mostra un incidente evitato in Olanda, è diventato virale e ha ottenuto moltissime visualizzazioni.
Meno noto è che ci siano stati anche incidenti, alcuni mortali, che gli strumenti con cui sono equipaggiate le Tesla non sono riuscite a prevedere ed evitare. Come quello costato la vita a Joshua Brown, sempre nel 2016.
Nel 2009, il volo Air france 447 si inabissò nel bel mezzo del oceano atlantico per un serie di circostanze sfortunate, tra cui l’azione di un sistema di intelligenza artificiale installato sull’airbus A330 che li trasportava da Rio de Janeiro verso Parigi.
Nel 2003 invece fu il sistema di intelligenza artificiale che guidava i missili Patriot ad abbattere ben due aerei amici: un tornado britannico ed un F18 della marina americana.
Come spesso accade, non è un solo fattore a causare il problema e non lo è stato nemmeno in questi incidenti, quindi attribuire la responsabilità di questi tristi eventi all’uso di software intelligenti e interattivi sarebbe superficiale. Ragionando per assurdo con questi parametri, potremmo considerare che tutti questi veicoli sono dotati di ruote, dunque la ragione degli incidenti risiede nella gomma.
LEGGI ANCHE:Il futuro dell’intelligenza artificiale è nel marketing creativo
Appare però evidente il denominatore comune dell’automazione estrema che richiede intervento umano minimo; la soglia di esperienza umana richiesta che si abbassa e l’incapacità di gestire un’emergenza quando gli avanzati sistemi si disinseriscono può causare gravi conseguenze.
La domanda giusta allora forse è: il vero rischio è che le intelligenze artificiali rendano noi umani stupidi? No, il grosso rischio e che ci imitino, diventando come noi ma molto, molto più potenti.
La rivolta delle macchine
Che dire della storia di Tay, il chatbot di Microsoft gestito da una intelligenza artificiale che, dopo poche ore di apprendimento iniziò a pubblicare tweet razzisti e sessisti?
Anche i sistemi AI di riconoscimento immagini possono essere tratti in inganno, consapevolmente o meno. Nel primo caso si sfruttano dei contro-algoritmi per ingannarli, nel secondo sono i loro stessi algoritmi a mancare il riconoscimento.
Così abbiamo il neonato con lo spazzolino che è percepito come un bambino con la mazza da baseball o la tartaruga riconosciuta come un fucile.
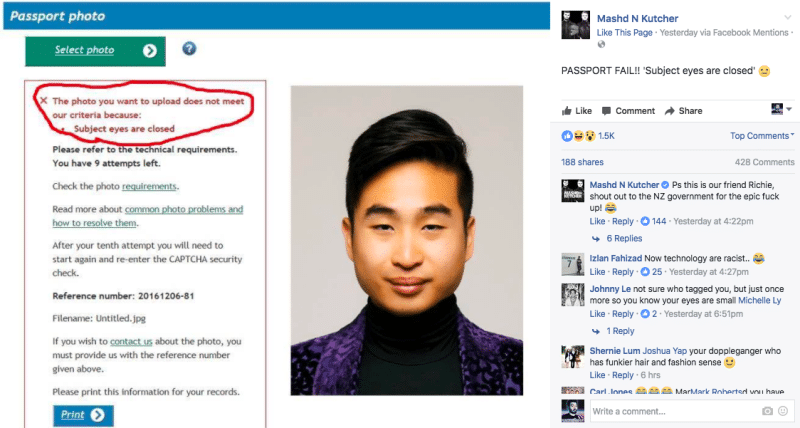
Vi sembrano esempi troppo lontani dalla vita di tutti i giorni? Ormai sono diffusi i sistemi di riconoscimento facciale: sono nelle macchine fotografiche e negli smartphone che usiamo ogni giorno e, alcuni di questi algoritmi (con i loro bias) hanno impedito ad un cittadino asiatico di ottenere il suo passaporto in pochi clic: il sistema di riconoscimento delle foto rifiutava le sue “perché aveva gli occhi chiusi”.
A causa dello stesso problema, la macchinetta fotografica di una blogger asiatica continuava a segnalarle che strizzava gli occhi.
Che dire dei sistemi di controllo di Facebook per verificare che gli utenti usino i propri veri nomi? Molti nativi americani si sono lamentati che il loro account fosse bloccato: cognomi come “creepingbear” (orso strisciante) non erano riconosciuti dal sistema come reali.
I sistemi di intelligenza artificiale sono ancora decisamente migliorabili: sono statisticamente impressionanti, ma inaffidabili in casi specifici.
LEGGI ANCHE:Ora puoi usare l’intelligenza artificiale di Google anche sul tuo sito
Cosa c’entrano le leggi di protezione del copyright con l’intelligenza artificiale?
I sistemi di intelligenza artificiale devono imparare, esattamente come i bambini umani imparano dagli adulti che hanno intorno: per imitazione. La differenza è che possono farlo molto più velocemente, analizzando una grande quantità di input (immagini o testo, per esempio) per rendersi sempre più autonomi.
Il problema, già evidenziato da alcuni ricercatori, è che se a questi sistemi vengono forniti dati distorti (biased), il sistema rifletterà lo stesso tipo di bias o distorsione.
L’anno scorso ricercatori della Princeton University hanno analizzato gli algoritmi di un sistema di elaborazione del linguaggio naturale chiamato GloVe. Dopo aver esaminato oltre 840 milioni di documenti nel Web, si scoprì che l’algoritmo stava velocemente sviluppando associazioni sessiste e razziste.
Parafrasando un vecchio adagio informatico (garbage in, garbage out, cioè spazzatura in entrata, spazzatura in uscita), si potrebbe affermare: bias in, bias out. Se i dati in entrata sono distorti, lo saranno anche le analisi in uscita.
I sistemi di AI hanno bisogno di grandi, enormi quantità di dati per imparare e questi dati devono essere facilmente accessibili, per diminuire tempi e costi di apprendimento. Si fa quindi ricorso a quelli di pubblico dominio o che non comportano rischi di azioni legali se usati: sono fonti che non hanno restrizioni o sono caratterizzate da licenze creative commons, per esempio.
Il più usato e popolare? Naturalmente Wikipedia. Se partiamo dal dato che solo una piccola percentuale (8.5%) di editor di Wikipedia ha dichiarato nel 2011 di essere di sesso femminile, tale fonte ha già in sé i bias cognitivi tipici maschili.
Altre fonti di pubblico dominio (quindi non coperte da alcun genere di copyright) sono invece datate, risalenti a oltre 70 anni fa e quindi con i bias tipici e più diffusi delle rispettive epoche.
Intelligenze artificiali e social network
Nel caso di Google, Facebook e altri social network, sono gli utenti stessi a fornire il materiale di addestramento per i sistemi di AI di queste aziende: ogni foto, video o immagini che carichiamo potrà essere usato a tale scopo.
Queste fonti di dati sono enormi, certo, ma anche sofferenti di tutti i bias di cui noi stessi siamo portatori.
LEGGI ANCHE:L’intelligenza artificiale? Non è mai stata una nemica
Secondo alcuni ricercatori si potrebbe almeno in parte attenuare questo peccato originale permettendo che le AI nella loro fase di addestramento possano accedere a database di miglior qualità ma molte delle fonti che potrebbero essere utilizzate sono coperte da copyright o pongono potenziali problemi legali se utilizzate.
In molti paesi, come gli USA (ma non solo) vige la regola del fair use, alla lettera uso leale. Permette, nonostante una certa opera sia coperta da copyright, di utilizzarla ugualmente per scopi d’informazione, critica o insegnamento, senza chiedere l’autorizzazione a chi ne detiene i diritti.
Secondo Amanda Levendowski, ricercatrice alla New York University specializzata proprio in questi temi, una interpretazione più elastica delle leggi di copyright e in particolare della dottrina dell’uso leale potrebbe rendere l’addestramento dei sistemi di intelligenza artificiale più affidabile e meno sofferente di bias.
Siamo certi che le opere coperte da copyright non siano del tutto esenti da bias, né che aumentare la quantità di dati utilizzabili sia la giusta strada, ma permettere l’accesso a fonti di qualità potrebbe contribuire ad equilibrare una situazione in cui le AI sembrano condannate a ripetere gli errori umani all’infinito.
“Se lo scopo del copyright è”, scrive nel suo articolo, “promuovere il progresso delle scienze e delle arti, allora non considerare fair use l’utilizzo delle opere protette per addestrare le AI è una contraddizione”.
I sistemi di intelligenza artificiale sono di aiuto e supporto in molti campi, ma siamo ancora in una fase in cui la supervisione umana è decisamente necessaria, in fase di addestramento ma anche di utilizzo: gli essere umani dovranno pian piano abituarsi ai nuovi compagni di vita e lavoro. L’integrazione responsabile tra sistemi di intelligenza artificiale ed esseri umani però è preziosa ed imprescindibile.
Pronto a cominciare?
Il tuo futuro nel digital inizia con un passo. Entra nel Campus Ninja





 Nel 2009, il volo Air france 447 si inabissò nel bel mezzo del oceano atlantico per un serie di circostanze sfortunate, tra cui l’azione di un sistema di intelligenza artificiale installato sull’airbus A330 che li trasportava da Rio de Janeiro verso Parigi.
Nel 2003 invece fu il sistema di intelligenza artificiale che guidava i missili Patriot ad abbattere ben due aerei amici: un tornado britannico ed un F18 della marina americana.
Come spesso accade, non è un solo fattore a causare il problema e non lo è stato nemmeno in questi incidenti, quindi attribuire la responsabilità di questi tristi eventi all’uso di software intelligenti e interattivi sarebbe superficiale. Ragionando per assurdo con questi parametri, potremmo considerare che tutti questi veicoli sono dotati di ruote, dunque la ragione degli incidenti risiede nella gomma.
LEGGI ANCHE: Il futuro dell’intelligenza artificiale è nel marketing creativo
Appare però evidente il denominatore comune dell’automazione estrema che richiede intervento umano minimo; la soglia di esperienza umana richiesta che si abbassa e l’incapacità di gestire un’emergenza quando gli avanzati sistemi si disinseriscono può causare gravi conseguenze.
La domanda giusta allora forse è: il vero rischio è che le intelligenze artificiali rendano noi umani stupidi? No, il grosso rischio e che ci imitino, diventando come noi ma molto, molto più potenti.
Nel 2009, il volo Air france 447 si inabissò nel bel mezzo del oceano atlantico per un serie di circostanze sfortunate, tra cui l’azione di un sistema di intelligenza artificiale installato sull’airbus A330 che li trasportava da Rio de Janeiro verso Parigi.
Nel 2003 invece fu il sistema di intelligenza artificiale che guidava i missili Patriot ad abbattere ben due aerei amici: un tornado britannico ed un F18 della marina americana.
Come spesso accade, non è un solo fattore a causare il problema e non lo è stato nemmeno in questi incidenti, quindi attribuire la responsabilità di questi tristi eventi all’uso di software intelligenti e interattivi sarebbe superficiale. Ragionando per assurdo con questi parametri, potremmo considerare che tutti questi veicoli sono dotati di ruote, dunque la ragione degli incidenti risiede nella gomma.
LEGGI ANCHE: Il futuro dell’intelligenza artificiale è nel marketing creativo
Appare però evidente il denominatore comune dell’automazione estrema che richiede intervento umano minimo; la soglia di esperienza umana richiesta che si abbassa e l’incapacità di gestire un’emergenza quando gli avanzati sistemi si disinseriscono può causare gravi conseguenze.
La domanda giusta allora forse è: il vero rischio è che le intelligenze artificiali rendano noi umani stupidi? No, il grosso rischio e che ci imitino, diventando come noi ma molto, molto più potenti.
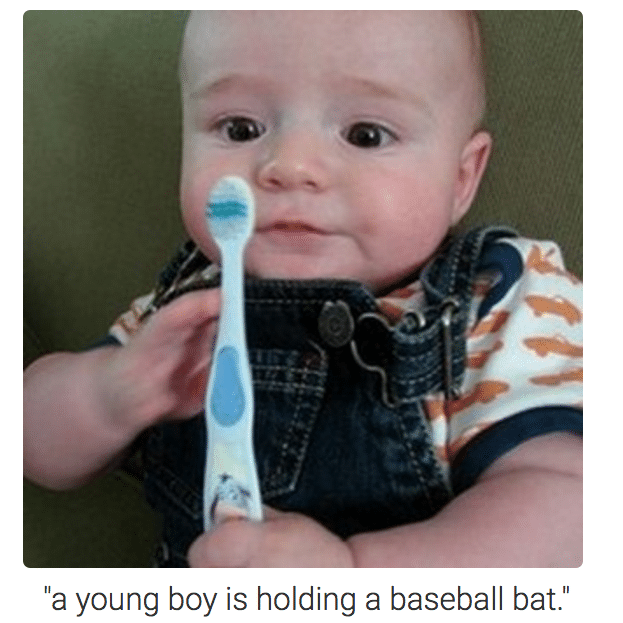 Vi sembrano esempi troppo lontani dalla vita di tutti i giorni? Ormai sono diffusi i sistemi di riconoscimento facciale: sono nelle macchine fotografiche e negli smartphone che usiamo ogni giorno e, alcuni di questi algoritmi (con i loro bias) hanno impedito ad un cittadino asiatico di ottenere il suo passaporto in pochi clic: il sistema di riconoscimento delle foto rifiutava le sue “perché aveva gli occhi chiusi”.
A causa dello stesso problema, la macchinetta fotografica di una blogger asiatica continuava a segnalarle che strizzava gli occhi.
Vi sembrano esempi troppo lontani dalla vita di tutti i giorni? Ormai sono diffusi i sistemi di riconoscimento facciale: sono nelle macchine fotografiche e negli smartphone che usiamo ogni giorno e, alcuni di questi algoritmi (con i loro bias) hanno impedito ad un cittadino asiatico di ottenere il suo passaporto in pochi clic: il sistema di riconoscimento delle foto rifiutava le sue “perché aveva gli occhi chiusi”.
A causa dello stesso problema, la macchinetta fotografica di una blogger asiatica continuava a segnalarle che strizzava gli occhi.
 Che dire dei sistemi di controllo di Facebook per verificare che gli utenti usino i propri veri nomi? Molti nativi americani si sono lamentati che il loro account fosse bloccato: cognomi come “creepingbear” (orso strisciante) non erano riconosciuti dal sistema come reali.
I sistemi di intelligenza artificiale sono ancora decisamente migliorabili: sono statisticamente impressionanti, ma inaffidabili in casi specifici.
LEGGI ANCHE: Ora puoi usare l’intelligenza artificiale di Google anche sul tuo sito
Che dire dei sistemi di controllo di Facebook per verificare che gli utenti usino i propri veri nomi? Molti nativi americani si sono lamentati che il loro account fosse bloccato: cognomi come “creepingbear” (orso strisciante) non erano riconosciuti dal sistema come reali.
I sistemi di intelligenza artificiale sono ancora decisamente migliorabili: sono statisticamente impressionanti, ma inaffidabili in casi specifici.
LEGGI ANCHE: Ora puoi usare l’intelligenza artificiale di Google anche sul tuo sito