











































Diventa free member
Vuoi leggere questo articolo e le altre notizie e approfondimenti su Ninja? Allora registrati e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.![]()
Diventa free member
Vuoi leggere questo articolo, le altre notizie e approfondimenti su Ninja? Allora lascia semplicemente nome e mail e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.
I siti delle aziende europee sono divisi in due categorie: quelli che non sono hostati da OVH e quelli che lo sono.
I webmaster lo sanno bene, e di recente anche molte aziende ne sono diventate consapevoli nel peggiore dei modi: giovedì 9 novembre 2017 sono andati offline tutti i datacenter OVH localizzati a Roubaix (RBX) e Strasburgo (SBG).
L’evento ha coinvolto una grossa fetta delle aziende italiane, rimaste senza sito e senza caselle di posta per l’intera giornata lavorativa!
Cosa è successo esattamente? Come è stato possibile? Si ripeterà?
Andiamo con ordine.
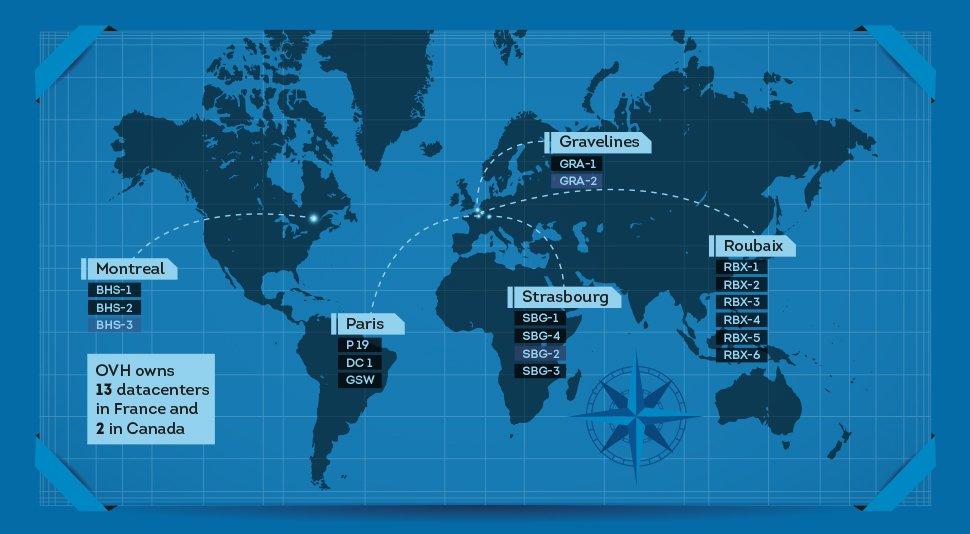
OVH è una delle più grandi aziende di cloud provider al mondo e la più grande in Europa. Fondata in Francia nel 1998, fornisce server dedicati, domini e servizi di telefonia. Ha all’attivo 15 datacenter (più tre in costruzione), con una capacità hosting di oltre 1 milione di server.
Giovedì 9 le sedi di Roubaix e Strasburgo, per un totale di nove datacenter, sono stati compromesse da due incidenti indipendenti tra loro, lasciando offline i siti e i servizi di posta di mezza Europa. Agli italiani interessa maggiormente il secondo, che copre l’Europa centrale e dell’est.
Ecco cosa è successo.

Luogo del guasto all'alimentazione di Strasburgo
Alle 7.23 un'interruzione di corrente lascia i tre data center di Strasburgo senza alimentazione per tre ore e mezza. I due cavi da 10 MVA ciascuno sono collegati alla stessa sorgente e allo stesso interruttore di circuito, per cui l’avvenuto danneggiamento di uno coinvolge anche l’altro.
È ovviamente previsto un sistema di backup, progettato per funzionare senza limiti di tempo. In caso di interruzione dell'alimentazione esterna, le celle ad alta tensione vengono automaticamente riconfigurate da un sistema di failover motorizzato. In meno di 30 secondi, e senza interruzioni di servizio, l’alimentazione dei datacenter dovrebbe essere ripristinata con a 20kV.
Il condizionale è d’obbligo, dato che nella pratica il comando di avvio dei generatori di backup non è mai partito.
I tecnici di OVH e dell’impresa di distribuzione elettrica locale riescono a riavviare le macchine verso le 10.00, cambiando manualmente le celle del generatore e ripristinando il cavo non danneggiato.
I router SBG tornano così online, ma i servizi di hosting, mail e cloud devono ancora essere ripristinati. La piena operatività dei siti si avrà intorno alle ore 23.00; per le mail occorrerà aspettare le 2.00 del venerdì.

L’emergenza è dunque rientrata in quasi 24 ore, un’intera giornata lavorativa durante la quale i telefoni di tutti i webmaster e web agency che si appoggiano a OVH squillano ininterrottamente, preannunciando le richieste di spiegazioni di migliaia di clienti.
Di pari passo, il call center del colosso dell’hosting è intasato di chiamate, senza che la domanda principale trovi una risposta: quando torneranno operativi tutti i servizi?
La multinazionale non è comunque stata avara di comunicazioni: l’account Twitter del CEO Octave Klaba è stato aggiornato ogni mezz’ora con frasi riprese poi dai vari account aziendali nazionali. Meno conosciuto ma altrettanto pubblico è il task manager di OVH, aggiornato dai tecnici e nel quale è possibile trovare i dettagli di ogni lavoro eseguito o in corso.
Cosa ha portato a questo scenario catastrofico? La risposta breve, fornita direttamente dal CEO, è questa:
«La griglia di alimentazione di SBG ha ereditato tutti i difetti di progettazione che erano il risultato delle piccole ambizioni inizialmente previste per quella posizione».

Più nel dettaglio, l’origine del problema risale al 2011. In quell’anno, OVH progetta di implementare nuovi datacenter a Strasburgo, ma decide di evitare i limiti di tempo associati ai permessi di costruzione, di modo da ricevere conferme operative prima di effettuare investimenti sostanziali. Per creare il datacenter SBG1 vengono così impiegati dei container. Due anni dopo, la stessa soluzione verrà utilizzata per l’SBG4.
Nel frattempo, sono nati SBG2 e SBG3, costruiti in torri da cinque o sei piani, come da standard OVH.
Con queste premesse, il tracollo di giovedì è stato reso possibile da due fattori:
Le cause esterne, già citate, invece, sono state:
Una congiuntura sfavorevole ha portato alla luce i mancati investimenti di OVH per garantire un servizio continuativo, caratteristica fondante di un cloud provider.
LEGGI ANCHE: Pensi che Facebook e Google siano gli unici a sapere tutto quello che fai? Sbagli

A seguito dei report sul problema, arriva la dichiarazione Octave Klaba, che ammette le responsabilità di OVH e annuncia le contromisure decise per il lungo termine:
«Anche se l'incidente è stato causato da automi di terze parti, non possiamo negare la nostra responsabilità per il crollo. Abbiamo approntato un piano d’azione su SBG affinché raggiunga lo stesso livello di standard degli altri siti di OVH. […] Si tratta di un piano di investimenti di 4-5 milioni di euro, che lanceremo subito e che ci consentirà di ripristinare la fiducia dei nostri clienti in SBG e OVH».
Le finalità degli interventi sulla sede di Strasburgo sono state così riassunte:
«Rivalutazione del design elettrico del sito, con conseguente decisione di abbandonare definitivamente l’utilizzo di container marittimi, come nel caso delle strutture di SBG 1 e 4, a vantaggio di data center “fissi” di elevata capacità, concepiti per infrastrutture di larga scala e ad alta affidabilità. I server ospitati a SBG 1 e 4 verranno migrati verso il data center SBG3, in costruzione, in modo che l’intero sito sia in grado di rispondere allo stesso livello di domanda raggiunto da tutti gli altri del Gruppo».
Il punto della situazione completo sugli incidenti accaduti a OVH il 9 novembre 2017 è consultabile a questo link, mentre per osservare da vicino l’evoluzione dei lavori presso le sedi OVH, il mezzo più diretto rimane l’account Twitter del CEO Oktave Klaba.
La griglia di alimentazione di SBG ha ereditato tutti i difetti di progettazione che erano il risultato delle piccole ambizioni inizialmente previste per quella posizione - Octave Klaba, CEO di OVH












