











































Diventa free member
Vuoi leggere questo articolo e le altre notizie e approfondimenti su Ninja? Allora registrati e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.![]()
Diventa free member
Vuoi leggere questo articolo, le altre notizie e approfondimenti su Ninja? Allora lascia semplicemente nome e mail e diventa un membro free. Riceverai Breaking News, Marketing Insight, Podcast, Tips&Tricks e tanto altro. Che aspetti? Tieniti aggiornato con Ninja.
Nella mio precedente articolo, Deep Web e Dark Web: l'altra faccia del web che conosci - Parte 1, ti avevo promesso che sarei andato oltre il Deep Web, per spiegarti un ulteriore pezzo di mondo molto poco esplorato, il Dark Web.
Procediamo subito!
Andiamo avanti nel Layer Cake e continuiamo a scendere. Troviamo il Dark Web, un ulteriore sottoinsieme del Deep Web.
Abbiamo detto che per accedere al vero Dark Web un browser qualsiasi non basta. E anche in questo caso occorre fare un ulteriore distinguo, tra la maggior parte dei contenuti e servizi che sono accessibili solo attraverso particolari browser o software (TOR e affini, o collegamenti VPN - Virtual Private Network) oppure, se vuoi veramente scendere il più in basso possibile ed accedere al altri contenuti, tramite altri strumenti.
In quest'ultimo caso inizia a fare veramente caldo, perché spaziamo dalle macchine virtuali apposite fino ad arrivare a parlare del mitico "Closed Shell System", del quale ti parlerò più avanti.
Ma procediamo con ordine e partiamo dal primo e più famoso protagonista del Dark Web: TOR.
La pagina del progetto TOR
Quando si parla di TOR si pensa immediatamente al "fratello oscuro di Firefox", ovvero ad un browser web che ci permette di navigare nel Dark Web senza lasciare tracce. Sappi che la mia personalissima considerazione è "Ma anche no!".
Iniziamo disambiguando. TOR è l'acronimo di "The Onion Router" che non è un browser, ma un sistema di comunicazione internet basato su uno specifico protocollo di comunicazione. Ad esempio, l'http (Hyper Text Transfer Protocol, protocollo di trasferimento di un ipertesto) è quell'insieme di regole e funzioni di comunicazione che è alla base del sistema con cui determinati tipi di informazioni sul web vengono trasmesse, nella fattispecie tra il nostro browser e il server web dell'hosting in cui è ospitato il sito che vogliamo visitare.
Di protocolli ce ne sono un sacco, sono regolamentati in dettaglio da appositi enti, ed è grazie a loro che le macchine riescono a dialogare tra loro.
L'onion routing è un protocollo in cui i dati (ad esempio quelli di navigazione, ma non solo) non girano "in chiaro" per la rete, ma vengono a monte incapsulati in vari strati di crittografia, da cui l'immagine della cipolla. Inoltre, non seguono le vie canoniche di tutti i dati, ma passano attraverso specifici nodi, i così detti onion router, che man mano "sbucciano" la cipolla (ovvero rimuovono uno strato di crittografia) fino alla consegna finale del pacchetto/messaggio/richiesta.
Complicato? No. Pensa alle matriosche. Il mio obiettivo è vedere il contenuto di un determinato sito. Questa mia richiesta non viene spedita immediatamente e in chiaro, ma viene prima creata "una matriosca".
L'informazione è quindi presa e messa in una serie di scatole sempre diverse, fino ad arrivare all'ultima. Sul retro dell'ultima, è scritto l'indirizzo del primo destinatario (nodo). Solo a questo punto viene inviata. Il primo nodo destinatario la riceve, la apre decrittandola, e trova un'altra matriosca su cui è scritto un destinatario cui inviarla. A questo punto il nodo si limita a inviare la matriosca al nodo successivo.
Quindi, il nodo ricevente non ha nessuna idea e possibilità di leggere quello che è il messaggio originale (ovvero la mia richiesta: "fammi vedere il contenuto di quel sito"), e agisce come un passacarte, conoscendo solo l'indirizzo del nodo mittente da cui riceve la matriosca e quello del nodo successivo cui spedirla. Quindi, la mia richiesta parte e viene "sbucciata" man mano e inoltrata fino a che non arriva a destinazione.
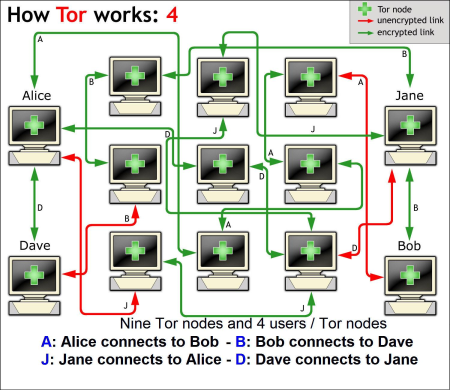
Un esempio di come funziona l'onion routing.
Ovviamente, la risposta alla mia domanda mi verrà data seguendo lo stesso algoritmo. L'obiettivo di tutto questo è rendere il più possibile private le comunicazioni, aumentando il livello di privacy e rendendo il tutto difficilmente intercettabile e oggetto di monitoraggio (cosa comunque non impossibile; pensa all'operazione Babylon).
Capito questo, il resto è facile. TOR Browser non è altro che una versione del browser Firefox opportunamente modificata per poter accedere a siti il cui primo livello è .onion, inaccessibili quindi da un comune web browser.
A prima vista, pare tutto molto semplice; si cerca un programma, lo si scarica e installa (o si usa la versione stand-alone), questo programma crea automaticamente delle connessioni e dei pacchetti criptati che instradano il mio traffico di navigazione attraverso vari nodi, e tutto questo mi permette di navigare in modo anonimo e frugare in giro in una parte dichiaratamente poco limpida della rete.
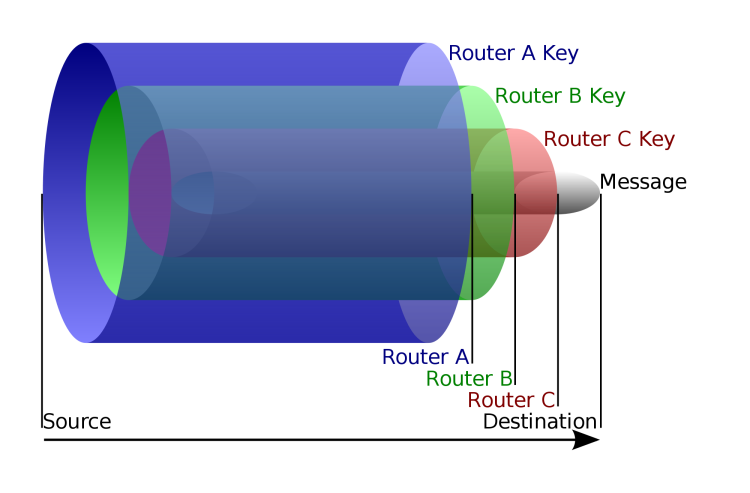
Come funziona la crittografia onion.
Voglio che il messaggio sia estremamente chiaro e semplice, per evitare fraintendimenti: “Don't try this at home”, ma nemmeno in ufficio, o a casa dell’amico, o dall’Internet Point dell’albergo.
Ovviamente, questo è solo uno degli strumenti di accesso, per la sola navigazione. Ci sono poi anche servizi analoghi per la chat (TORchat) e per la posta elettronica come SIGAINT, che ultimamente pare abbia avuto qualche problemino di raggiungibilità (se vuoi approfondire, puoi leggere l'ultimo articolo in merito su Securityaffairs).
Abbiamo detto che il Dark Web non è indicizzato. E allora come faccio io a trovare quello che cerco? Beh, facile, in due modi:
Ovviamente i servizi basati sul protocollo TOR sono tra i più gettonati, ma non sono gli unici. A supporto si trovano cataste di altri escamotage per cercare di lasciare il minor numero possibile di tracce in giro. Lasciando da parte roba più complessa come sistemi di crittografia o steganografia, pensa solo a tutti i servizi temporanei, il cui contenuto è soggetto ad uno specifico tempo di vita prima di essere definitivamente distrutto. O anche a sistemi che permettono alle mie richieste di essere instradate per altre vie, cercando quindi di occultare la fonte da cui derivano.
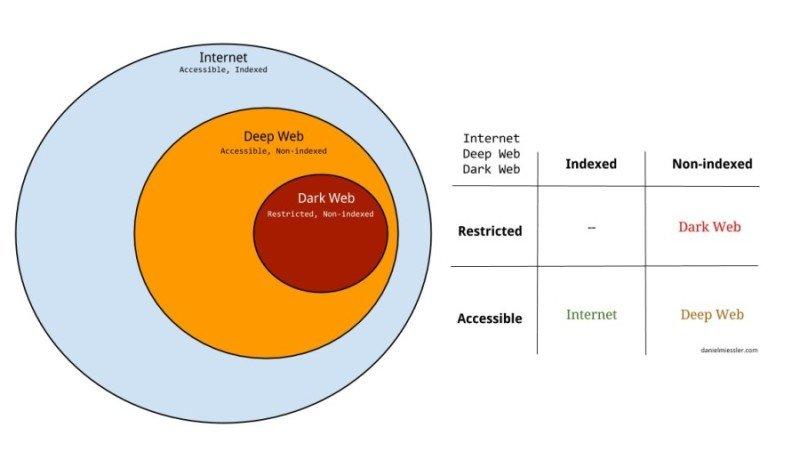
Quello che vedi sopra è un piccolo schema riassuntivo che ti lascio per fare velocemente il punto dei concetti base che ho cercato di spiegarti.
Ma non penserai mica che è finita qui? Assolutamente no, possiamo andare ancora avanti, e scendere ulteriormente. Ci sono ancora altri livelli e un sacco di considerazioni tecniche e non da fare in merito. Te lo racconto tutte nella prossima parte.
Mi raccomando, stay turned.
Deep Web e Dark Web. Cosa sono esattamente? Quali sono i vari livelli che li compongono e quali sono le differenze? Si sa che esistono e se ne parla, ma rimangono per molti concetti oscuri. Un piccolo viaggio verso le profondità inesplorate del web, per poterlo comprendere tecnicamente.












